欢迎来到桌面AGI时代!六台M4 Pro本地大模型推理实测
合集 · 全面分析 深度解析 (54)
-
M2芯片深度解析, 有惊喜, 有失望! 不是苹果想要的那颗芯
 16:04
16:04
-
M1 Ultra: 全面评测与深度解析! 苹果牌胶水行不行
 25:49
25:49
-
「芯片简史」苹果, 白手起家, 长路漫漫, 道阻且长
 22:05
22:05
-
天玑9000:卷!发哥真就硬卷!
 9:31
9:31
-
2022年了,iPhone咋还不用Type-C?14Pro也许有戏!
 10:44
10:44
-
M1 Max性能全解密! 凑齐7台Mac, 全配置挖掘Mac的小秘密!
 19:59
19:59
-
苹果13 Pro: 高刷机制全解密, 2400帧相机一帧一帧看!
 20:27
20:27
-
【科普】什么是计算摄像?费这大劲,图个啥?真就是手机未来!?
 17:58
17:58
-
【硬核】何为鸿蒙?和安卓的区别到底是什么?别再扯套壳了
 15:29
15:29
-
骁龙888怎么了? 三星5nm工艺深度解析! 小米11被高通坑了?
 15:34
15:34
-
【干货】你绝对没听过的iPhone12深度解析!取消充电器的真相, iPhone12定位, 激光雷达, ProRAW!
 20:16
20:16
-
岂止剪辑,M1 Mac全面测评!为什么M1这么猛?离Pro级芯片还有多远?
 17:43
17:43
-
ARM Mac与Apple Silicon:全面解读苹果自研芯片,Intel Mac还能不能买,WWDC没告诉你的,都在这里了
 20:39
20:39
-
【干货】Apple Glass提前“发布”,理性分析,全面预测,从技术的角度告诉你Apple Glass到底有什么!
 19:16
19:16
-
【全程高能】iPhone12:理性分析,全面预测!高刷屏,无刘海,四摄,A14,需求与技术,理性预测,全程干货,建议提前喝水!
 18:34
18:34
-
iPad Pro 2020:这不是iPad,这是ARM Laptop!
 14:33
14:33
-
第一台iPad怎么买? 暑期教育优惠·iPad选购指南
 13:12
13:12
-
灵动岛鸡肋? 主战场并非iPhone!iPhone 14 Pro测评(上)
 7:17
7:17
-
为什么过度锐化?iPhone在毁掉你的照片?iPhone 14 Pro测评(中)
 13:56
13:56
-
为什么“核多力量大”?i9-13900K深度测评
 13:06
13:06
-
iPhone 14 Plus: 会成为下一部mini吗?iPhone 15系列布局
 7:02
7:02
-
ChatGPT为什么厉害?天网维形还是村头大妈?
 9:56
9:56
-
臭打游戏之外,还能干些什么?13代i9HX+RTX4080 宏碁掠夺者战斧18性能测试
 9:08
9:08
-
M2 Pro工科生产力测试,苹果留了一手?Mac生产力系列(上)
 15:35
15:35
-
为什么Mac=视频创作? AI时代下还会是吗?Mac生产力系列(下)
 10:57
10:57
-
苹果Vision Pro: 靠什么从虚拟走向现实?
 7:25
7:25
-
新款Mac Studio硬核体验,赛博朋克2077能跑多少帧?
 7:40
7:40
-
A17性能全面预测,关于iPhone15还有些你不知道的
 8:33
8:33
-
不再过度锐化?A17性能如何?iPhone 15发布会5分钟回顾
 5:51
5:51
-
iPad Pro M4: AI性能深度分析!苹果大模型要来了
 9:48
9:48
-
一次讲透!工科生用Mac,体验如何?
 9:27
9:27
-
不只是家庭影院!买了6个HomePod之后,我的建议是....
 8:49
8:49
-
A17 NPU性能实测!为什么只有iPhone 15 Pro能用?Apple Intelligence深度解读(一)
 13:21
13:21
-
部落还是联盟?魔兽世界Mac完美适配!
 7:12
7:12
-
A18,为AIGC而生!iPhone16系列AI性能深度测试
 12:10
12:10
-
35瓦GPU挑战700亿参数大模型!苹果M4 Max/M4性能深度分析
 12:13
12:13
-
假“手表”之名,行“计算”之实!Apple Watch系列十年回顾
 9:13
9:13
-
Mac集群跑DeepSeek等大模型?六台M4 Pro本地大模型推理实测
 8:58
8:58
-
速度媲美官网?满血M3 Ultra推理6000亿参数DeepSeek R1
 11:18
11:18
-
光追级UI!?WWDC 2025 Liquid Glass技术解析!
 4:14
4:14
-
建模太阳磁场、运行本地大模型!为什么学生都爱用Macbook Air?
 8:25
8:25
-
【深度】用2T内存的Mac跑AI!对话EXO创始人Alex Cheema
 20:41
20:41
-
iPhone 17 Air:苹果折叠屏的前奏
 8:19
8:19
-
诚意,诚意,还是诚意!iPhone 17苹果秋季发布会全解析
 5:12
5:12
-
全网最细!iPhone 17系列AI性能分析
 14:47
14:47
-
越级表现,超越Pro!M5芯片AI性能深度分析
 12:43
12:43
-
iPhone Air深度评测:极简是复杂的最高级形式
 8:55
8:55
-
AI一键剪辑,小白救星!Apple创作全家桶深度体验
 8:46
8:46
-
【硬核教程】教你搭建Mac AI集群!2TB显存,运行万亿参数大模型!
 11:25
11:25
-
【深度】苹果牌AI计算卡!M5 Max AI性能深度分析!
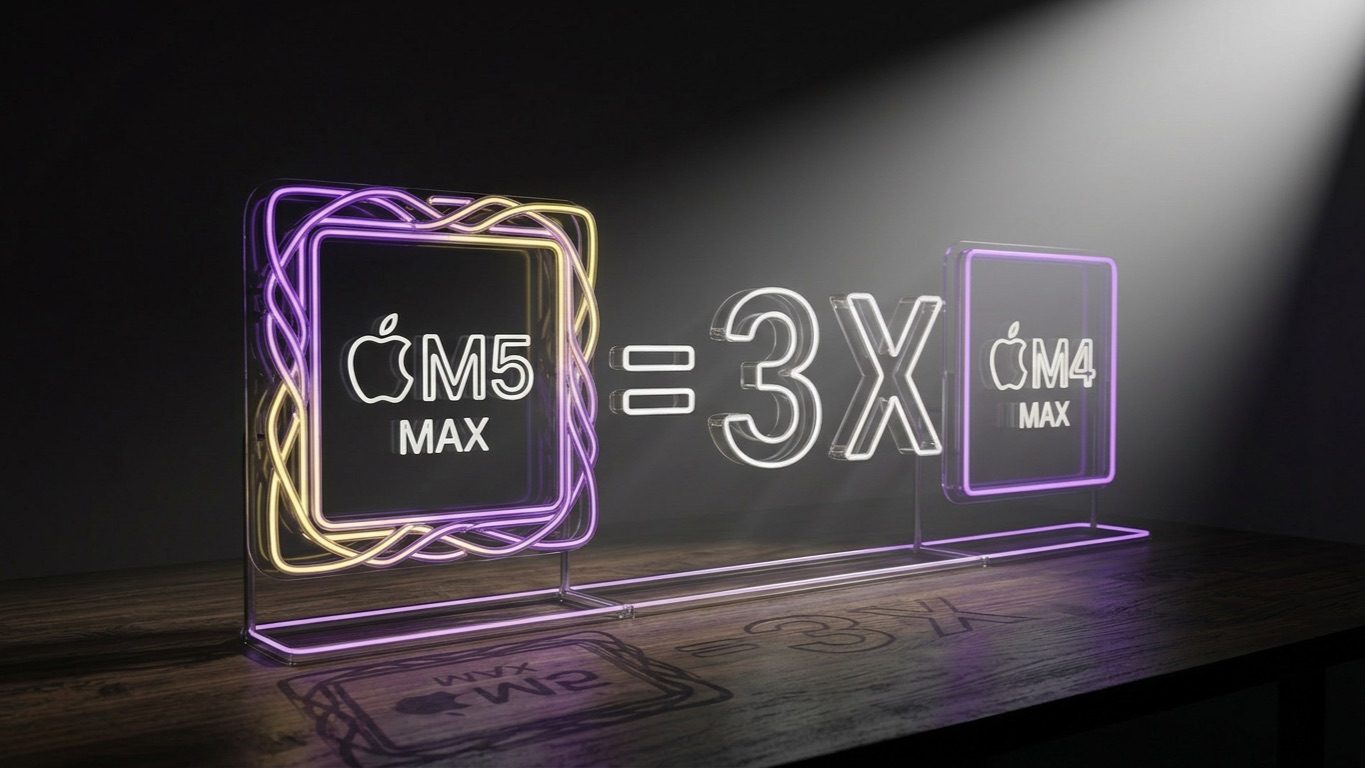 13:05
13:05
-
【深度】MacBook Neo: 苹果最“差”的 Mac,为什么反而最重要?
 6:00
6:00
-
NVIDIA DGX Spark:128G统一内存!桌面AI超算Coding实测
 8:15
8:15
-
Windows 用户的本地 AI 方案!雷神水冷迷你AI工作站实测体验
 9:29
9:29
-
苹果给AI生图,交出了一份标准答案
 2:39
2:39
Description
为什么大家都在用Mac做本地大模型推理呢? 为什么Mac适合于本地运行DeepSeek等大模型呢? 六台顶配M4 Pro集群的推理性能如何? 本视频主要测试Llama 3.1 70B,DeepSeek R1 70B等小体量蒸馏模型可以采用相同方式运行。 (视频快做完了,exoLabs支持DeepSeek了T.T)
Comments
昨天预约的时候还以为是6个mini推原生deepseek了。。
♥ 334 ↩ 22
我的个天,功耗才200w,这简直是服务器机房的不二之选
♥ 309 ↩ 11
看完了视频,觉得有两个问题,第一个就是mac集成芯片目前的带宽是存在瓶颈并且远远落后与同时代独显的,4090的带宽1tb/s,5090是1.8tb/s,第二就是我刷到的几乎所有mac跑大模型的视频都闭口不谈散热和首字延迟这两个弱项,开头说独显内存贵,结果后面发测评结果70b大模型两张3090的推理速度要六台顶配mac才能追得上,看不出mac的方案到底便宜在哪了
♥ 250 ↩ 76
之前就算过了,性价比最高的还是CPU推理,16通道48G内存,13k就能搞定,然后CPU两颗xeon8680+ es4一共4k,超微x13dei差不多6000,各种周边2k搞定,25k就能搞定一套能跑起来R1-V3的工作站,只要张老师的六分之一[吃瓜]
♥ 247 ↩ 44
之前X上看到个1个M4Max+7个M4pro跑deepseek-r1完整版的[笑哭]
♥ 209 ↩ 15
我现在最最希望的就是国行Apple intelligence能和ds合作,这样消费者满意苹果股价也能蹭热度涨一波,何乐而不为?库克加油啊[笑哭]
♥ 181 ↩ 32
如果老黄的project digits出了,国内零售价应该不低于2.5w,15w大约6个digits,应该是768g统一内存,老黄自己说可以联机,但没说最高几台,但这东西的算力(单精度浮点)大概也就3060水平,同是arm架构但是功耗要远高于m4 mini达到60w,反正能跑就是了,凑12台感觉应该能跑全量级deepseek,但速度估计就是龟速,总之能用,费用么30w,如果用v100显卡(16g)大约100张,光卡的费用(pcie转接卡+sxm2的卡约2500,100张就2000一张)那也要20w,全用m4mini大约62.5w(25台),如果用p100(一张约800,大约用100张),要8w,这个省,但速度基本不能看了,p40(24g)什么的更是重量级价格和p100相近,没半精度只能单精度,速度更慢,由于没有半精度所以要120张,大约11w(900元批量可能600左右那就是跟p100价格没区别),2080ti22g(价格2500批量估计能压到2000大约要70张)14w,3090(5.5k-6k,有nvlink,大约要60张,按批发价5k)那就是30w,3080(魔改20g价格3500左右),4060ti16,4070,rtx 2000ada之流,价格普遍4000上下,这些卡普遍100张40w起步了,还都是卡的价格,老黄稍微发点力老黄赢,不发力苹果赢如果AMD/INTEL发力,带核显的处理器只要内存够最终赢家还是它们,但体验上肯定不太好,内存速度低普通机器内存容量有极限,但是一般的量化模型性价比最高
♥ 115 ↩ 24
我以为能跑多大的呢,70b两张2080ti不就行了,造价不出6k
♥ 87 ↩ 62
本地跑这也太创造需求了,个人联网用足够,买一次硬件花的钱够api调用用到退休的。如果是公司有安全考虑,那让它买8卡H800的服务器好了,为生产力工具省钱不是员工该考虑的事
♥ 75 ↩ 6
如何你也用Mac跑过本地大模型,欢迎在评论区分享你的测试结果[星星眼][星星眼]本次测试设备为6*M4 Pro,64G内存,使用exoLabs与雷电五网桥连接!
♥ 74 ↩ 12
著名人工智能社区 Hugging Face 的工程师马修·卡里根展示了在本地运行 Deepseek-R1 的完整硬件和软件设置。他使用的是 670B 模型,没有进行蒸馏,采用 Q8 量化,实现了完整质量。总成本仅为 6000 美元。硬件方面,主板使用技嘉 MZ73-LM0 或 MZ73-LM1,它们具有2个 EPYC 插槽,提供24个 DDR5 RAM 通道。CPU 方面,可以使用2个任何 AMD EPYC 9004 或 9005 CPU。
♥ 67 ↩ 4
m4 丐版 Mini 跑 14b 模型和我笔记本 3060 跑 8b 一样快[doge],而且风扇都不带超 20% 转速的
♥ 66 ↩ 13
个人和小团队, 如果不是图片和视频需求, 秒选 M4 集群或者 Mac studio,无他功耗低,可以全天不关机。 4090X 4 先不说价格, 看看功率就能搞死人。机柜彻底排除,功耗都不说,吵到死。
♥ 63 ↩ 7
除非有能力本地运行全参数模型,或者有学习微调需求的话,不建议任何人部署本地模型,要知道ai大模型可不止语言大模型,难道想每个都部署吗,调用api是最好的,价格现在已经很便宜了,与其去学习如何本地部署大模型,不如去学习如何本地部署集成各种api的框架去使用api
♥ 62 ↩ 21
4090魔改48g跑70b deepseek-r1就有17.5tok/s,八台苹果性价比还是不够看
♥ 57 ↩ 28
哪有什么性价比…… 按照6台mac mini 20 token/s 算,一年24小时x365天运行也就生成6.3亿的token,跑的还是70b模型 Deepseek v3 (685b)模型现在生成一百万token才收费两块钱,生成质量远高于70b llama的同时只要¥1200。根据地方电费价格,可能都没mac电费贵。 有这钱送给苹果用来生成低质量文本,为啥不直接给Deepseek?
♥ 43 ↩ 47
这是真的性价比极低啊……epyc高带宽,或者2080ti多卡同样的价格性能会好很多吧……
♥ 37 ↩ 34
本地跑个r1蒸馏70b完全没问题,这两天ds官方api接口被打爆,就用本地了。。
♥ 30 ↩ 12
我最近琢磨家用部署大模型有两个方案,一个是amd 9600x之类的配合4根48g内存条总共192g运行内存,算上主板电源机箱大概6000多(不包括显卡)如果要配合未来可能发布的5080 24g版本,可以改成4*32g的内存条(128g运行内存),整机价格大概16000以内。另一个是amd epyc9192之类的+12根64g内存条总共768g运行内存+单路主板,大概不到4万。方案一还挺有可行性的。
♥ 27 ↩ 14