35瓦GPU挑战700亿参数大模型!苹果M4 Max/M4性能深度分析
合集 · 全面分析 深度解析 (54)
-
M2芯片深度解析, 有惊喜, 有失望! 不是苹果想要的那颗芯
 16:04
16:04
-
M1 Ultra: 全面评测与深度解析! 苹果牌胶水行不行
 25:49
25:49
-
「芯片简史」苹果, 白手起家, 长路漫漫, 道阻且长
 22:05
22:05
-
天玑9000:卷!发哥真就硬卷!
 9:31
9:31
-
2022年了,iPhone咋还不用Type-C?14Pro也许有戏!
 10:44
10:44
-
M1 Max性能全解密! 凑齐7台Mac, 全配置挖掘Mac的小秘密!
 19:59
19:59
-
苹果13 Pro: 高刷机制全解密, 2400帧相机一帧一帧看!
 20:27
20:27
-
【科普】什么是计算摄像?费这大劲,图个啥?真就是手机未来!?
 17:58
17:58
-
【硬核】何为鸿蒙?和安卓的区别到底是什么?别再扯套壳了
 15:29
15:29
-
骁龙888怎么了? 三星5nm工艺深度解析! 小米11被高通坑了?
 15:34
15:34
-
【干货】你绝对没听过的iPhone12深度解析!取消充电器的真相, iPhone12定位, 激光雷达, ProRAW!
 20:16
20:16
-
岂止剪辑,M1 Mac全面测评!为什么M1这么猛?离Pro级芯片还有多远?
 17:43
17:43
-
ARM Mac与Apple Silicon:全面解读苹果自研芯片,Intel Mac还能不能买,WWDC没告诉你的,都在这里了
 20:39
20:39
-
【干货】Apple Glass提前“发布”,理性分析,全面预测,从技术的角度告诉你Apple Glass到底有什么!
 19:16
19:16
-
【全程高能】iPhone12:理性分析,全面预测!高刷屏,无刘海,四摄,A14,需求与技术,理性预测,全程干货,建议提前喝水!
 18:34
18:34
-
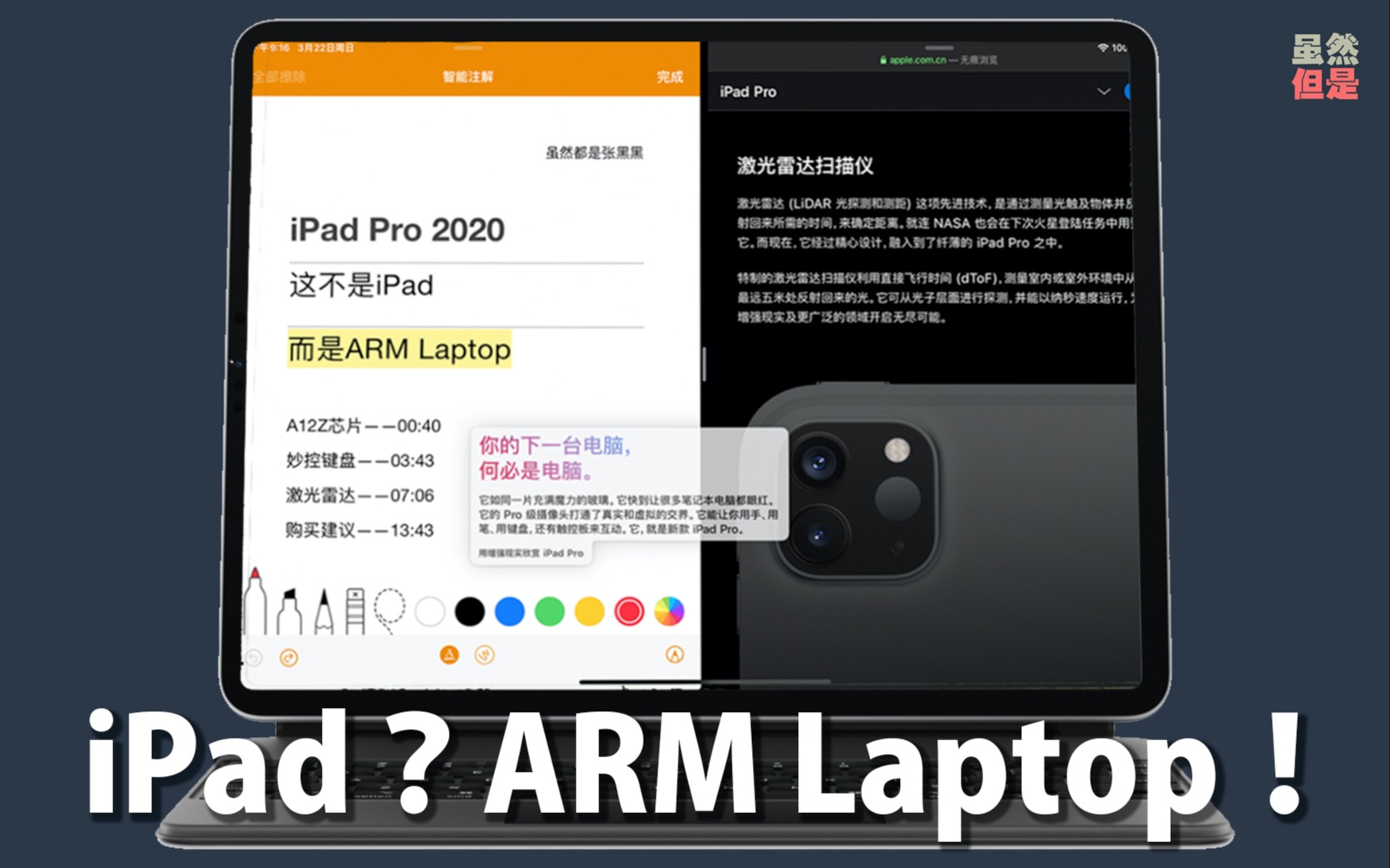
iPad Pro 2020:这不是iPad,这是ARM Laptop!
 14:33
14:33
-
第一台iPad怎么买? 暑期教育优惠·iPad选购指南
 13:12
13:12
-
灵动岛鸡肋? 主战场并非iPhone!iPhone 14 Pro测评(上)
 7:17
7:17
-
为什么过度锐化?iPhone在毁掉你的照片?iPhone 14 Pro测评(中)
 13:56
13:56
-
为什么“核多力量大”?i9-13900K深度测评
 13:06
13:06
-
iPhone 14 Plus: 会成为下一部mini吗?iPhone 15系列布局
 7:02
7:02
-
ChatGPT为什么厉害?天网维形还是村头大妈?
 9:56
9:56
-
臭打游戏之外,还能干些什么?13代i9HX+RTX4080 宏碁掠夺者战斧18性能测试
 9:08
9:08
-
M2 Pro工科生产力测试,苹果留了一手?Mac生产力系列(上)
 15:35
15:35
-
为什么Mac=视频创作? AI时代下还会是吗?Mac生产力系列(下)
 10:57
10:57
-
苹果Vision Pro: 靠什么从虚拟走向现实?
 7:25
7:25
-
新款Mac Studio硬核体验,赛博朋克2077能跑多少帧?
 7:40
7:40
-
A17性能全面预测,关于iPhone15还有些你不知道的
 8:33
8:33
-
不再过度锐化?A17性能如何?iPhone 15发布会5分钟回顾
 5:51
5:51
-
iPad Pro M4: AI性能深度分析!苹果大模型要来了
 9:48
9:48
-
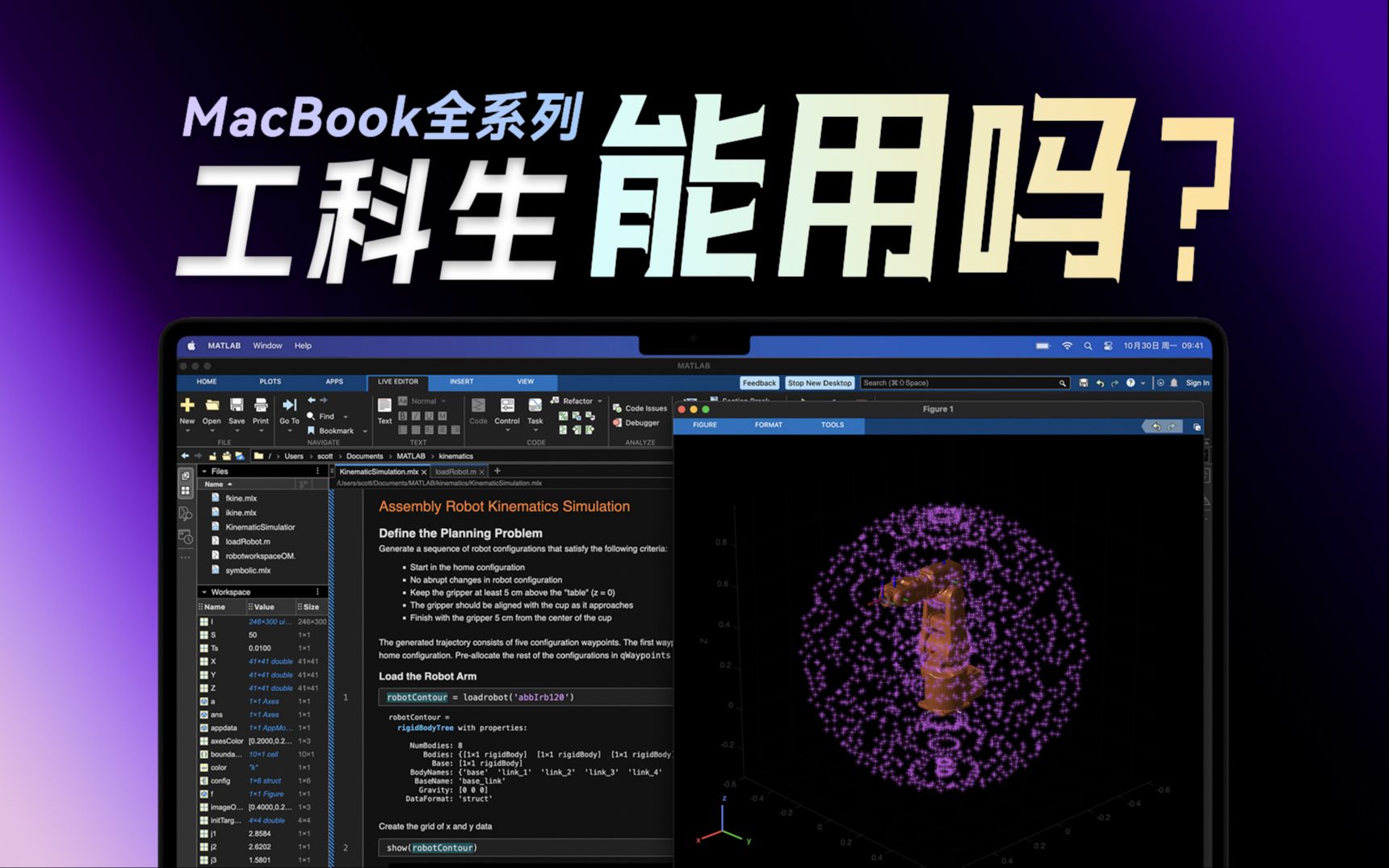
一次讲透!工科生用Mac,体验如何?
 9:27
9:27
-
不只是家庭影院!买了6个HomePod之后,我的建议是....
 8:49
8:49
-
A17 NPU性能实测!为什么只有iPhone 15 Pro能用?Apple Intelligence深度解读(一)
 13:21
13:21
-
部落还是联盟?魔兽世界Mac完美适配!
 7:12
7:12
-
A18,为AIGC而生!iPhone16系列AI性能深度测试
 12:10
12:10
-
35瓦GPU挑战700亿参数大模型!苹果M4 Max/M4性能深度分析
 12:13
12:13
-
假“手表”之名,行“计算”之实!Apple Watch系列十年回顾
 9:13
9:13
-
Mac集群跑DeepSeek等大模型?六台M4 Pro本地大模型推理实测
 8:58
8:58
-
速度媲美官网?满血M3 Ultra推理6000亿参数DeepSeek R1
 11:18
11:18
-
光追级UI!?WWDC 2025 Liquid Glass技术解析!
 4:14
4:14
-
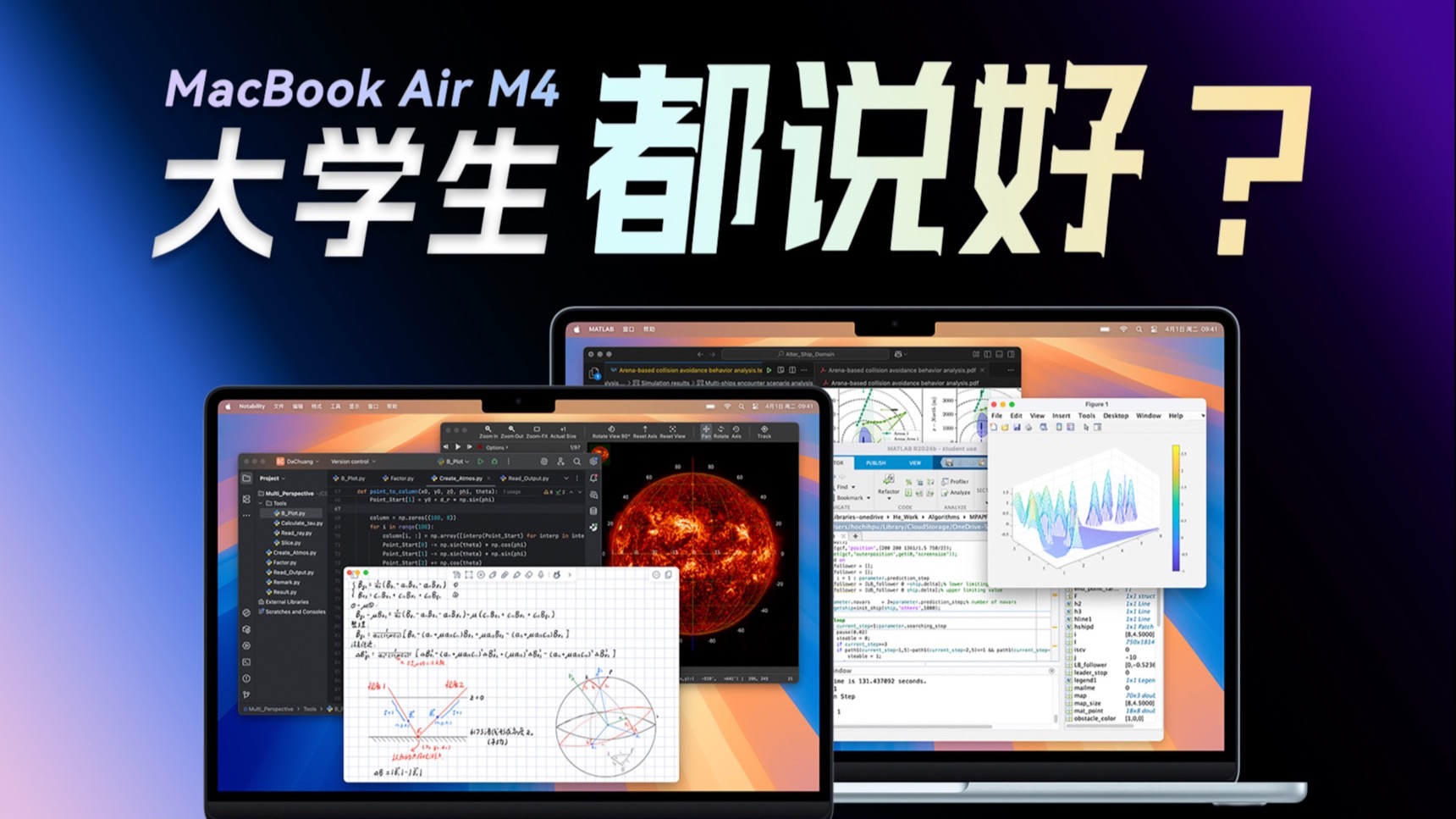
建模太阳磁场、运行本地大模型!为什么学生都爱用Macbook Air?
 8:25
8:25
-
【深度】用2T内存的Mac跑AI!对话EXO创始人Alex Cheema
 20:41
20:41
-
iPhone 17 Air:苹果折叠屏的前奏
 8:19
8:19
-
诚意,诚意,还是诚意!iPhone 17苹果秋季发布会全解析
 5:12
5:12
-
全网最细!iPhone 17系列AI性能分析
 14:47
14:47
-
越级表现,超越Pro!M5芯片AI性能深度分析
 12:43
12:43
-
iPhone Air深度评测:极简是复杂的最高级形式
 8:55
8:55
-
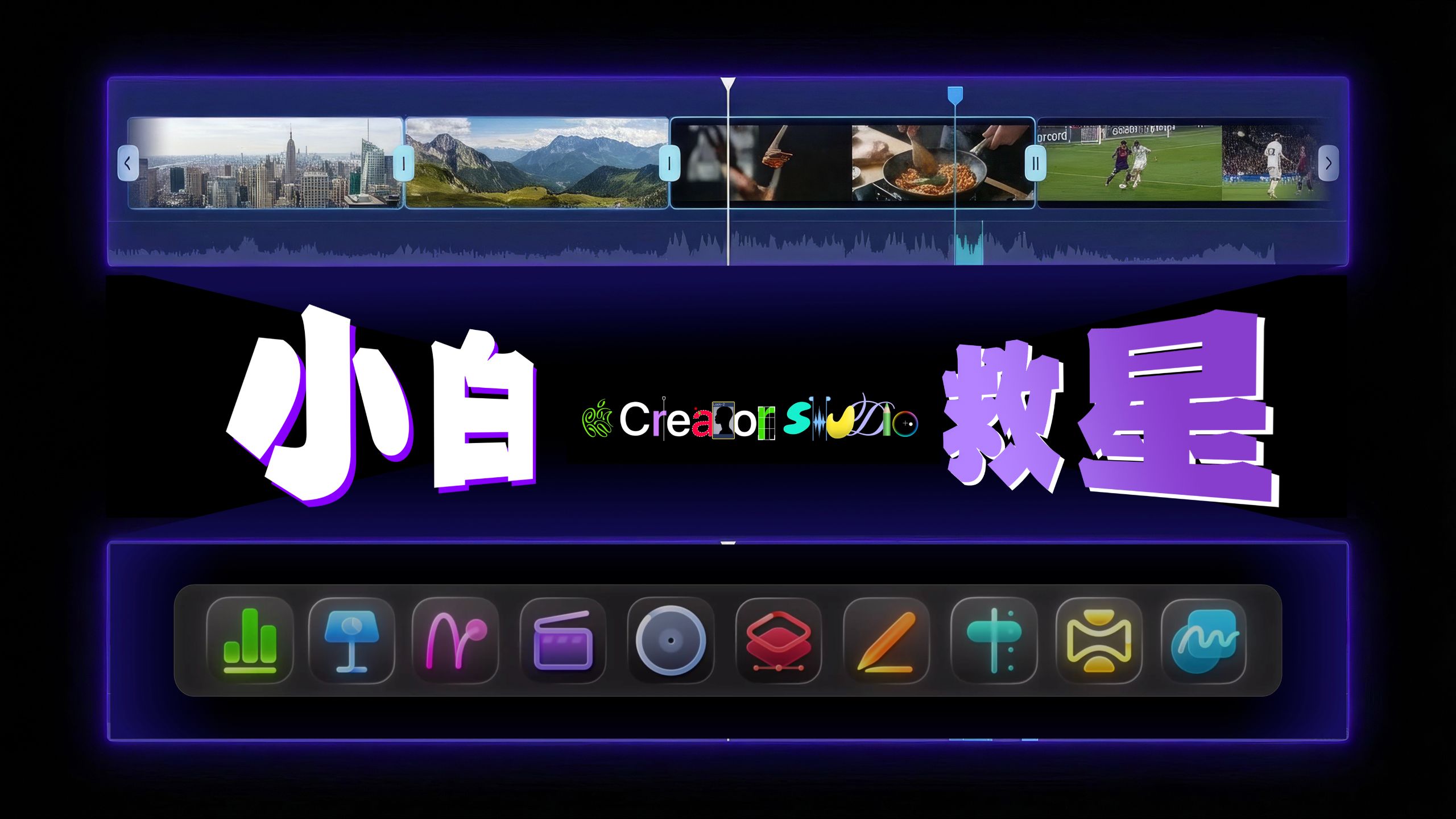
AI一键剪辑,小白救星!Apple创作全家桶深度体验
 8:46
8:46
-
【硬核教程】教你搭建Mac AI集群!2TB显存,运行万亿参数大模型!
 11:25
11:25
-
【深度】苹果牌AI计算卡!M5 Max AI性能深度分析!
 13:05
13:05
-
【深度】MacBook Neo: 苹果最“差”的 Mac,为什么反而最重要?
 6:00
6:00
-
NVIDIA DGX Spark:128G统一内存!桌面AI超算Coding实测
 8:15
8:15
-
Windows 用户的本地 AI 方案!雷神水冷迷你AI工作站实测体验
 9:29
9:29
-
苹果给AI生图,交出了一份标准答案
 2:39
2:39
Description
2020年6月,苹果宣布向ARM平台过渡。我想称其为一场“平淡的革命”。它平淡到让许多普通用户感觉不到任何变动,Mac似乎还是那个Mac。然而,隐藏于表面的,却是苹果在四年时间里完成了一次生态大迁移,M4系列芯片也用性能证明了苹果的创新实力。这确实是一场科技领域的革命,我们有幸亲历其中。
Comments
去年看了几个国外评测后,就买了192GB 的 M2 Ultra 来高强度跑推理快1年了,推理速度基本上和带宽挂钩。 刚开始还追大参数量的模型,后面换成支持大上下文的MoE模型,更好用,整个项目重构/翻译这种任务吃100G以上显存轻轻松松,所以RAM越大越好,当然现在可以等mamba架构的模型出来多几个,这个架构的优点是大上下文对内存涨幅和推理速度影响都不大。 微调需求是没有的,直接上大段文本做RAG来增强/修正模型的知识就行了,用它接了一个本地保密等级高(wireguard的多层跳板 + mTLS加密)的项目当推理后端,就放在我的工作间的货架上,显示器都不接,日常占用120G,项目赚了几十个Ultra顶配的钱,等M4 Ultra出来再买几个放不同地点做异地灾备。这玩意最适合几个人的小团队干大事,启动成本很低,维护性和可靠性非常不错。 我买了官翻192GB的Ultra之后就经常刷库存看看,有多少人知道192GB的官翻Ultra今年只有半个月是库存充足的,剩下时间都是断货的[脱单doge]
♥ 351 ↩ 69
你能想象我入手m4max来替换m1max的原始冲动竟然是为了一个叫做狂热运输2的游戏么[笑哭][笑哭]。实测下来,14900K(64g内存)+4080S甚至并不能在绝对意义上干掉m1max 64G,大部分场景下winter+nv的帧数表现波动幅度太大,而M1max却能维持一个可玩的帧率。当然,在入坑大语言模型后,发现本地部署模型竟然也是如此丝滑,以至于现在有点迫不及待地想看到自己的M1max对比M4max表现了。当然,之后应该就是海鲜市场出掉m1max给自己回血了[吃瓜][吃瓜][吃瓜]
♥ 385 ↩ 40
gpu整体来说还是稍微令人失望,m4max没能超过m2ultra,m4pro肯定也比不过m2max了,根据up提供的gemma2 27b q4数据来看,自己的m2pro满血是10t,相比m2max是16t,m4pro大概也就13-14t,相比cpu的提升,gpu只能说差强人意,不过考虑到m4mini相比同配置满血m2max的studio便宜2.5-3k,cpu还遥遥领先,整体还是值得
♥ 194 ↩ 25
终于有个测大模型的up了,那些个剪视频的太浪费mac内存了
♥ 136 ↩ 7
哥哥太专业了!!
♥ 89 ↩ 4
Mac的ai推理还是老问题,它不足以用一个能满足阅读需求的速度(15tokens/s左右)跑70b级别的模型,也不能够以一个合适的价格买到能运行相似质量的moe模型的内存。这方面它甚至不如牙膏厂的6980p或者amd的9755。 如果只是使用30b级别的模型,一张3000块钱的16g 4060ti或者1600块的转接V100已经足够让你尝试一下这些模型(选择3bit的量化),而加到5500左右买个3090已经能很好的使用这类模型,这里还不提n卡这边的flash attention之类的加速。
♥ 145 ↩ 34
很关注这次m4的CPU提升,up能测下Matlab性能吗?我的科研和非线性薛定谔方程求解有关,需要CPU有很强的ode和fft性能,我自己的环境下7945hx和m1在不爆内存的情况下用时几乎一致,很好奇m4的表现
♥ 76 ↩ 17
这两天刚上手试了试微调,自己电脑肯定跑不动,云算力不好用,想着整个mac试试,反正就调14b的结果看完视频发现微调居然要95g[灵魂出窍]放弃了,还是先调小的吧 再问下up,m4max本地推70b系统内存一共占用了多少,我想买的48g的m3max会不会不够用,31b的有会占多少,谢谢up[脱单doge]
♥ 79 ↩ 6
除了硬盘,基本都拉满了,128gb内存,我也是要跑大模型
♥ 70 ↩ 45
音乐制作感觉m1max甚至都够用,就是会爆内存,但是m4max这次升级真的很大,我今年才1w多入了m1max超顶配版,感觉可以过一两年买m4了,看up从m1分析到现在感觉时间过得好快[脱单doge]
♥ 60 ↩ 14
视频里出现的本地AI对话软件应该是LM Studio,挺好用的,挂🪜后可以连接hugging face下载超级多的模型,足够日常使用了
♥ 60 ↩ 7
up一看就不玩AI绘画,测的太敷衍啦,居然只测了sd2.0 这个唯一没有人用的版本,sd1.5 sdxl 和flux的测试全都没有,我当时就是因为这些测试关注你的[笑哭]
♥ 84 ↩ 44
理解了,m4如果不推理模型,一律16G性价比最好,如果推理千问14b,因为内存只有三分之二可以当显存,而且上下文也会占用一些显存,而且m4的性能运行27b左右的模型只剩5tokens/s,所以不宜买超过24G的M4 Mac mini,实在想推理27B以上的,得m4 pro,32G内存以上!
♥ 48 ↩ 21
所以m4 max多少钱?也是三千多吗,up说性能就是m4max,说价格就是m4,emmmm。。。
♥ 62 ↩ 4
千万不要轻易相信,它这个说的只是基本上0上下文时吐出的tokens,而不是你一直问它问题的时候吐出tokens的数目,一直问它问题,它会迅速变慢,而Nvidia的变慢速度比苹果要慢的多,apple加载gpt o1 preview给的回答: 在运行大型语言模型时,GPU的计算能力对模型的推理速度和效率有直接影响。NVIDIA的RTX 4090相比Apple的M4 Max,确实在性能上有明显优势。 当上下文长度增加时,模型需要处理更多的计算,特别是在自注意力机制中,计算复杂度与序列长度的平方成正比。GPU性能较弱的设备在处理长上下文时,计算速度会显著下降,导致推理时间变长。这不仅影响到生成输出token的速度,也影响到模型的“思考”时间。 因此,您在M4 Max上运行大型模型时,确实可能会遇到处理长上下文导致性能下降的问题。这是当前硬件在处理大型深度学习模型时的一个挑战,也是选择高性能GPU的重要性所在。
♥ 50 ↩ 1
视频做的超棒,要是有m4 pro对比就好了。准备买来跑个本地的中小llm模型试试
♥ 34 ↩ 5
非常牛的测评,全网独家
♥ 39
太感谢您了,我最近就是一直在想着弄一台mac来进行大模型的推理,自己的4090装在itx里面又没法加卡,学校的A100也不好做一些自己的事情,大部分测评都是跑个分,找了很久都没找到这样的模型推理方面的对比,就一直在不同配置之间纠结,这个视频完美解决了我的困惑[脱单doge]
♥ 44 ↩ 7
[doge]不换m4max 128G测试怎么行?
♥ 32 ↩ 4