速度媲美官网?满血M3 Ultra推理6000亿参数DeepSeek R1
合集 · 全面分析 深度解析 (54)
-
M2芯片深度解析, 有惊喜, 有失望! 不是苹果想要的那颗芯
 16:04
16:04
-
M1 Ultra: 全面评测与深度解析! 苹果牌胶水行不行
 25:49
25:49
-
「芯片简史」苹果, 白手起家, 长路漫漫, 道阻且长
 22:05
22:05
-
天玑9000:卷!发哥真就硬卷!
 9:31
9:31
-
2022年了,iPhone咋还不用Type-C?14Pro也许有戏!
 10:44
10:44
-
M1 Max性能全解密! 凑齐7台Mac, 全配置挖掘Mac的小秘密!
 19:59
19:59
-
苹果13 Pro: 高刷机制全解密, 2400帧相机一帧一帧看!
 20:27
20:27
-
【科普】什么是计算摄像?费这大劲,图个啥?真就是手机未来!?
 17:58
17:58
-
【硬核】何为鸿蒙?和安卓的区别到底是什么?别再扯套壳了
 15:29
15:29
-
骁龙888怎么了? 三星5nm工艺深度解析! 小米11被高通坑了?
 15:34
15:34
-
【干货】你绝对没听过的iPhone12深度解析!取消充电器的真相, iPhone12定位, 激光雷达, ProRAW!
 20:16
20:16
-
岂止剪辑,M1 Mac全面测评!为什么M1这么猛?离Pro级芯片还有多远?
 17:43
17:43
-
ARM Mac与Apple Silicon:全面解读苹果自研芯片,Intel Mac还能不能买,WWDC没告诉你的,都在这里了
 20:39
20:39
-
【干货】Apple Glass提前“发布”,理性分析,全面预测,从技术的角度告诉你Apple Glass到底有什么!
 19:16
19:16
-
【全程高能】iPhone12:理性分析,全面预测!高刷屏,无刘海,四摄,A14,需求与技术,理性预测,全程干货,建议提前喝水!
 18:34
18:34
-
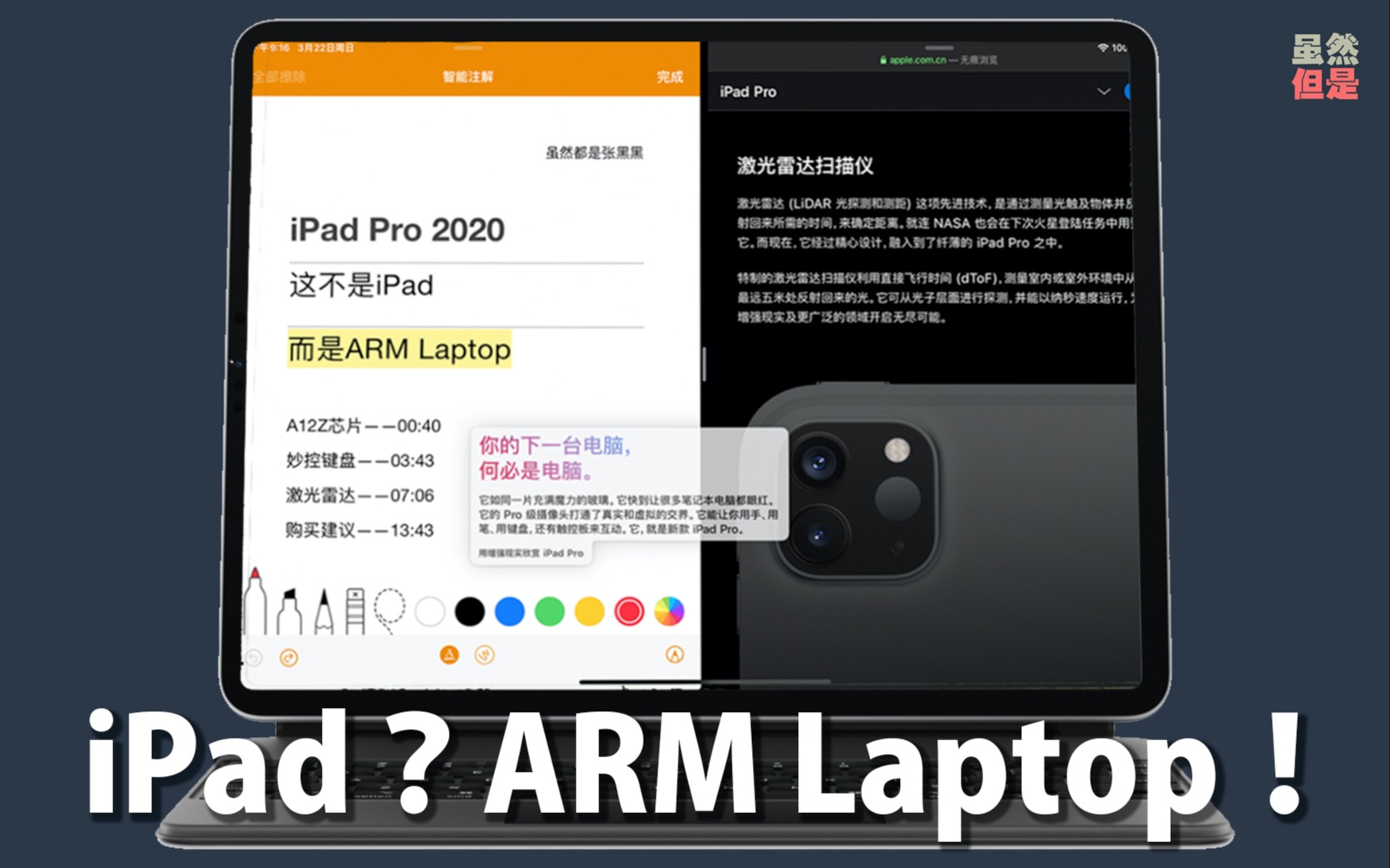
iPad Pro 2020:这不是iPad,这是ARM Laptop!
 14:33
14:33
-
第一台iPad怎么买? 暑期教育优惠·iPad选购指南
 13:12
13:12
-
灵动岛鸡肋? 主战场并非iPhone!iPhone 14 Pro测评(上)
 7:17
7:17
-
为什么过度锐化?iPhone在毁掉你的照片?iPhone 14 Pro测评(中)
 13:56
13:56
-
为什么“核多力量大”?i9-13900K深度测评
 13:06
13:06
-
iPhone 14 Plus: 会成为下一部mini吗?iPhone 15系列布局
 7:02
7:02
-
ChatGPT为什么厉害?天网维形还是村头大妈?
 9:56
9:56
-
臭打游戏之外,还能干些什么?13代i9HX+RTX4080 宏碁掠夺者战斧18性能测试
 9:08
9:08
-
M2 Pro工科生产力测试,苹果留了一手?Mac生产力系列(上)
 15:35
15:35
-
为什么Mac=视频创作? AI时代下还会是吗?Mac生产力系列(下)
 10:57
10:57
-
苹果Vision Pro: 靠什么从虚拟走向现实?
 7:25
7:25
-
新款Mac Studio硬核体验,赛博朋克2077能跑多少帧?
 7:40
7:40
-
A17性能全面预测,关于iPhone15还有些你不知道的
 8:33
8:33
-
不再过度锐化?A17性能如何?iPhone 15发布会5分钟回顾
 5:51
5:51
-
iPad Pro M4: AI性能深度分析!苹果大模型要来了
 9:48
9:48
-
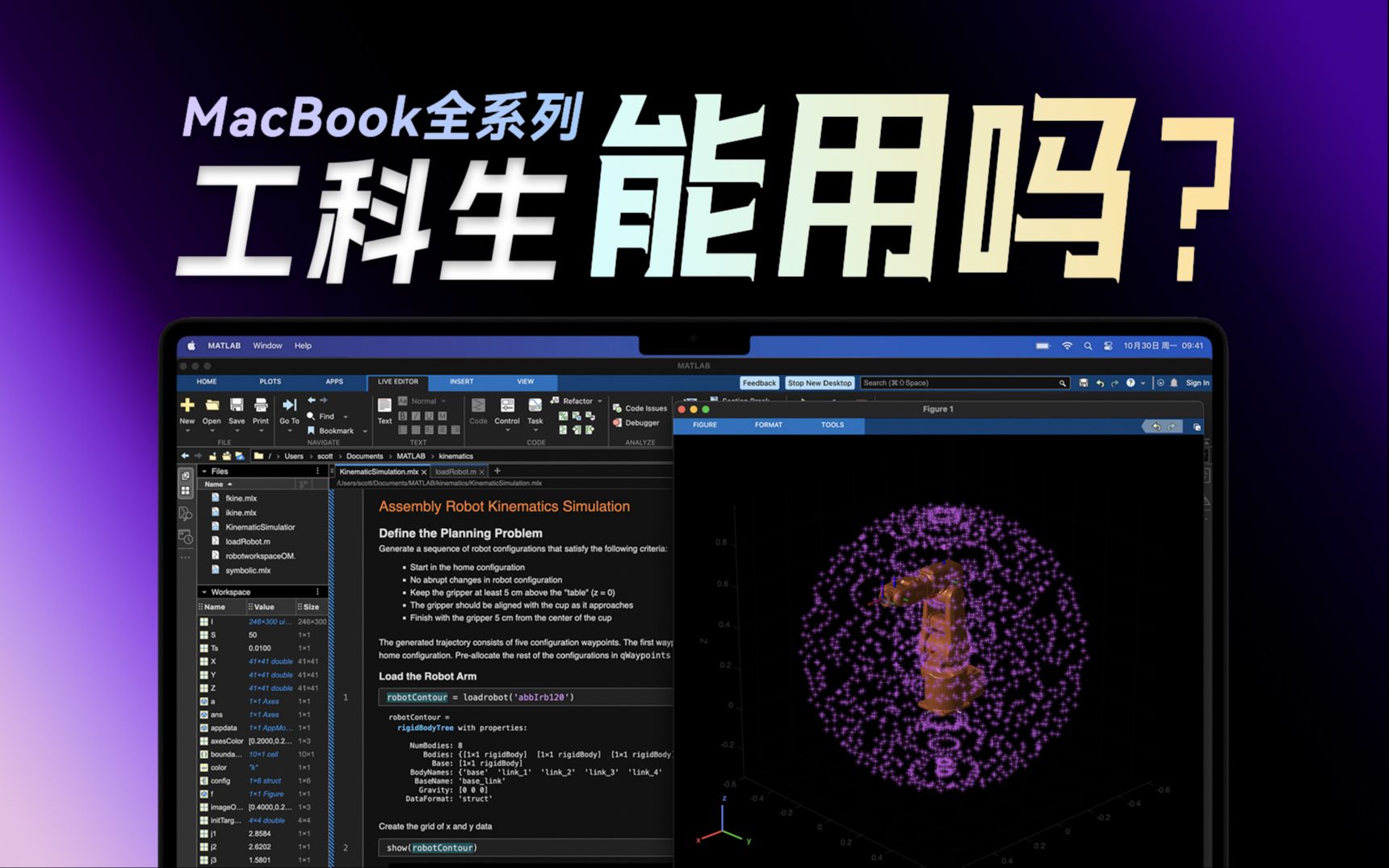
一次讲透!工科生用Mac,体验如何?
 9:27
9:27
-
不只是家庭影院!买了6个HomePod之后,我的建议是....
 8:49
8:49
-
A17 NPU性能实测!为什么只有iPhone 15 Pro能用?Apple Intelligence深度解读(一)
 13:21
13:21
-
部落还是联盟?魔兽世界Mac完美适配!
 7:12
7:12
-
A18,为AIGC而生!iPhone16系列AI性能深度测试
 12:10
12:10
-
35瓦GPU挑战700亿参数大模型!苹果M4 Max/M4性能深度分析
 12:13
12:13
-
假“手表”之名,行“计算”之实!Apple Watch系列十年回顾
 9:13
9:13
-
Mac集群跑DeepSeek等大模型?六台M4 Pro本地大模型推理实测
 8:58
8:58
-
速度媲美官网?满血M3 Ultra推理6000亿参数DeepSeek R1
 11:18
11:18
-
光追级UI!?WWDC 2025 Liquid Glass技术解析!
 4:14
4:14
-
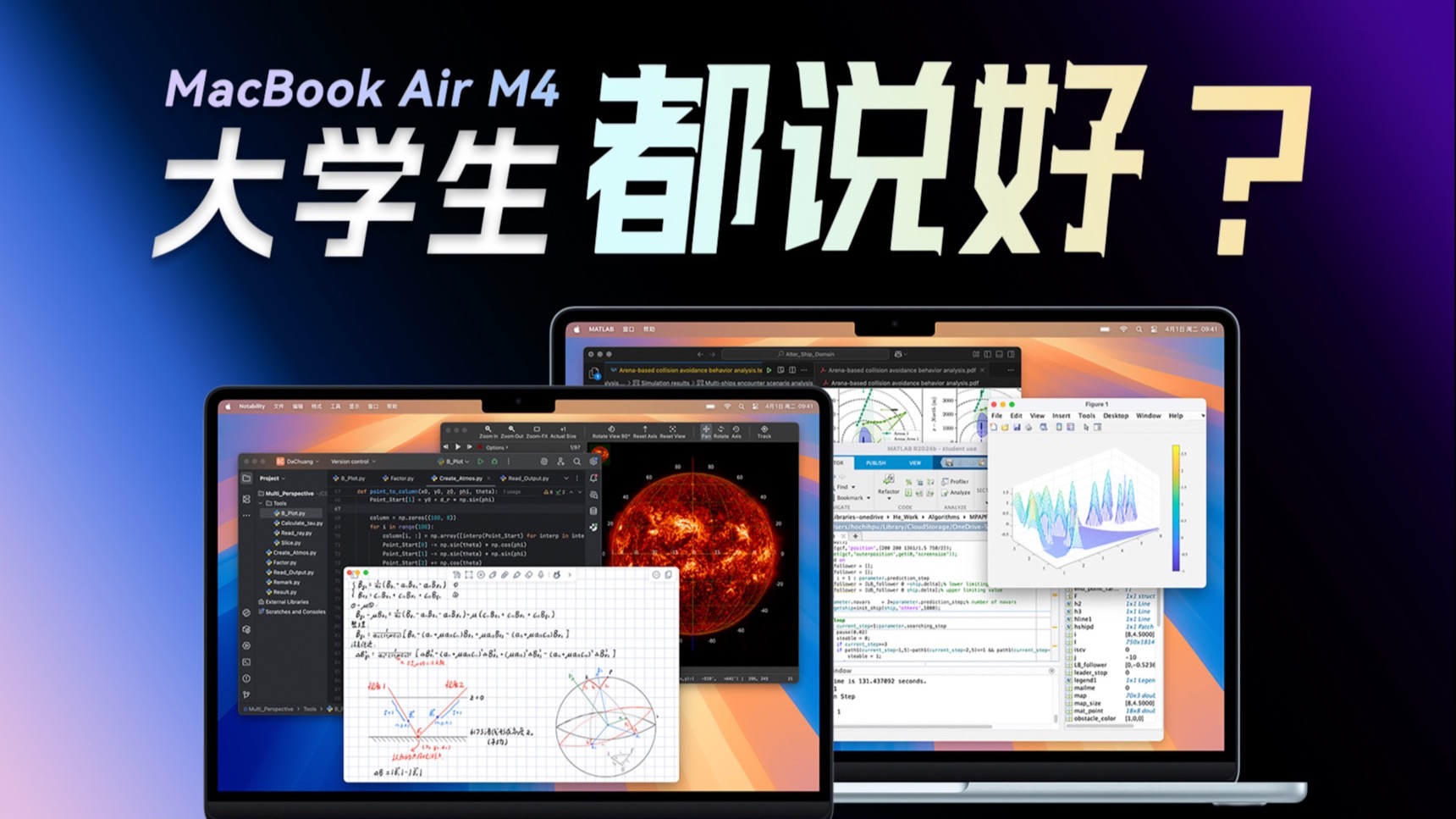
建模太阳磁场、运行本地大模型!为什么学生都爱用Macbook Air?
 8:25
8:25
-
【深度】用2T内存的Mac跑AI!对话EXO创始人Alex Cheema
 20:41
20:41
-
iPhone 17 Air:苹果折叠屏的前奏
 8:19
8:19
-
诚意,诚意,还是诚意!iPhone 17苹果秋季发布会全解析
 5:12
5:12
-
全网最细!iPhone 17系列AI性能分析
 14:47
14:47
-
越级表现,超越Pro!M5芯片AI性能深度分析
 12:43
12:43
-
iPhone Air深度评测:极简是复杂的最高级形式
 8:55
8:55
-
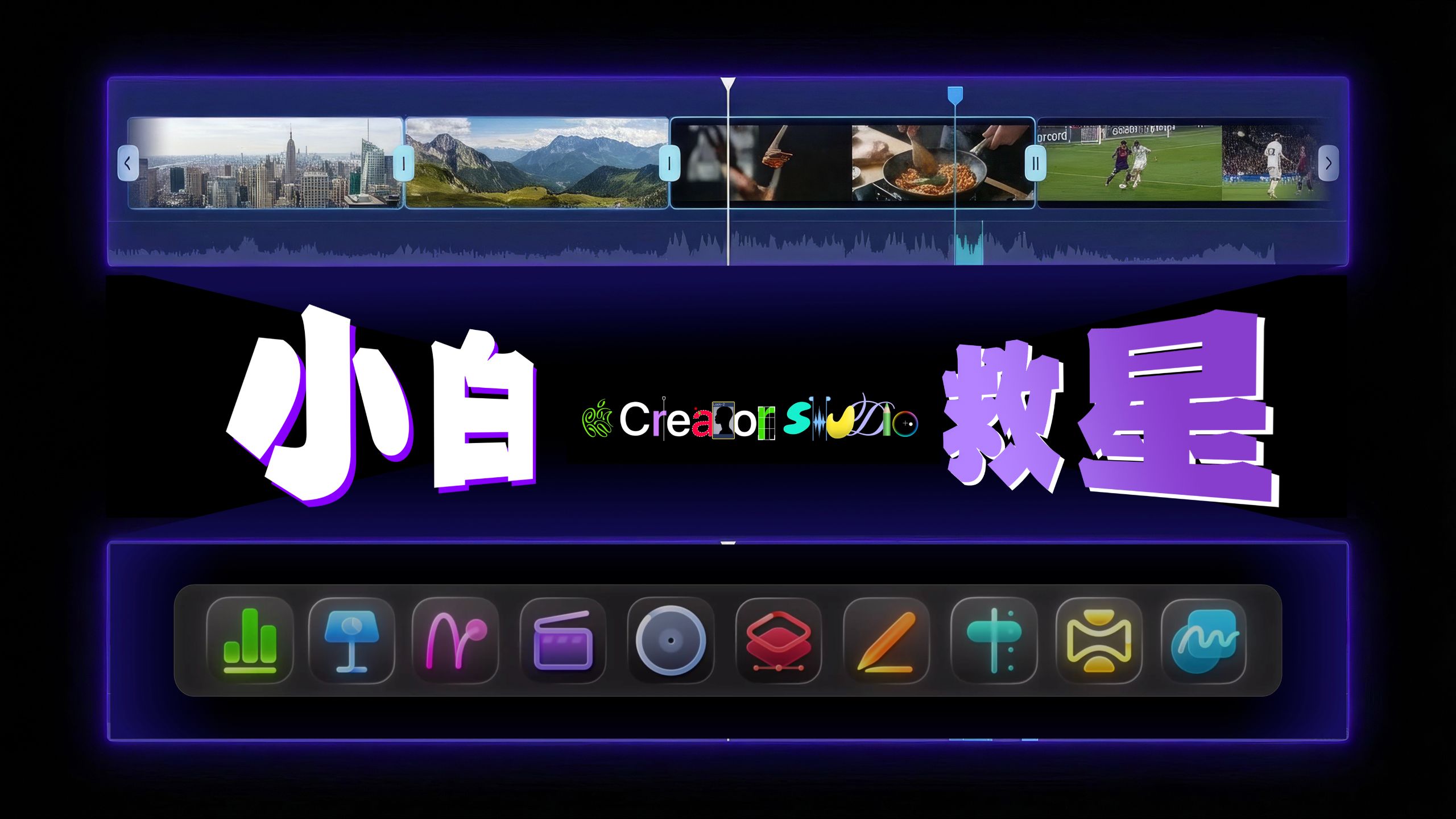
AI一键剪辑,小白救星!Apple创作全家桶深度体验
 8:46
8:46
-
【硬核教程】教你搭建Mac AI集群!2TB显存,运行万亿参数大模型!
 11:25
11:25
-
【深度】苹果牌AI计算卡!M5 Max AI性能深度分析!
 13:05
13:05
-
【深度】MacBook Neo: 苹果最“差”的 Mac,为什么反而最重要?
 6:00
6:00
-
NVIDIA DGX Spark:128G统一内存!桌面AI超算Coding实测
 8:15
8:15
-
Windows 用户的本地 AI 方案!雷神水冷迷你AI工作站实测体验
 9:29
9:29
-
苹果给AI生图,交出了一份标准答案
 2:39
2:39
Description
速度媲美官网?!满血M3 Ultra推理DeepSeek R1 671B 4bit性能如何?
Comments
[doge]这个有教育优惠,6万7就可以拿走
♥ 618 ↩ 54
这个视频做的好,但也有不少误导。特别是截屏出来的那个速度比8卡A100快,很能吸引人并且被广泛传播。但实际上答主只测试了单用户的token输出速度,又拿了60W功耗很低的说法,实际上大模型推理设备还会有TTFT(首个token输出时间)、多用户并发的总token速度、平均到单用户的功耗这些指标,以及你用的ollama这样的llama.cpp方案根本不是production scale,而是个人玩家尝鲜型的。 用Mac推理,很多人都不提Time to First Token。就是你输入一段文字给他,他要首先进行预填充prefill,之后才能输出首个字。稍长一些的上下文,比如1K输入,就需要等待十几秒。 第二个是A100你用了llama.cpp暂且不说这个方案是不是最优,人家8卡能服务大概100个并发,而如果是Mac的并发增加很快就不行了。 第三就是功率也是有很强的误导性。8卡A100,或者8卡H100,平均到单个用户头上功率还真就只有30-50W。这个误导性类似于【ChatGPT一天耗电70万,人脑功率30W】,是典型的偷换概念,ChatGPT一天服务上亿用户,平均到单用户头上功率和人脑就是一样的。
♥ 543 ↩ 34
我没记错的话, 最晚在一年前, 那会ds还没火, 就已经有老哥发现Mac很适合跑极大参数量的MoE模型, 并且还发现在一些任务上效果比自己去微调稠密模型(那会还是主流)来得更好. 在目前来看苹果两次撞准了端侧推理的方向, 这个Mac Studio已经是现在版本答案了, 不过AI还是发展太快了, 将来说不定又整出啥新东西也未可知.
♥ 528 ↩ 54
此外,我发现国内吹苹果适合本地推理LLM的这些博主一般会避免讨论一个问题,包括录屏也会避免拍到一个信息,Prefill速度,你可以理解成大语言模型理解上下文所需要使用的时间,这将主要影响在较大上下文的情况下,用户等首个Token输出需要等多久。一个外网有趣的测试,上下文达到4K的时候,模型的TTFT大概是30s左右,也就是说,你和模型多轮对话的时候,模型开始吐出第一个词的速度会越来越慢,甚至大于半分钟……
♥ 527 ↩ 33
LLM性能 小白测评数据 32/70B 8bit:与M2U没差别 70B全精度:仅M3U可运行4.74tokens 671B 3bit: 21.88tokens,4bit:9.65tokens 张黑黑数据 671B 4bit:15.78 tokens(gguf),19.17(mlx),60w功耗
♥ 257 ↩ 31
卧槽这也太牛逼了,我最近在考虑Mac Studio部署Qwen2.5Max 32B的版本,感觉预算3W就能搞下来,效果据说和671B的R1差不多
♥ 249 ↩ 27
官网价格:M3 Ultra +512G 统一内存+1T固态硬盘 =74249
♥ 174 ↩ 30
就是dense和moe的区别,r1就是37B。这个本质目的就是权衡知识量和推理成本的方法,衡量指标也是参数量杠杆
♥ 155 ↩ 16
请勿恰饭坑人。苹果在AI硬件领域上至少落后英伟达6年以上, 自从M1上线之后, 创始人跑路, 就决定了这一点。7w5大洋,正规企业能配两台并发6~7的q4 20token/s的服务器, q8 11.25token/s。只有没能力做任何事情的小白才会采购苹果的机子跑AI。
♥ 150 ↩ 47
估计很多小公司会买,7万5预算,不算贵。
♥ 143 ↩ 36
有没有像我一样的,专业数据都不懂,看个热闹的。
♥ 88 ↩ 2
这么算下来,每生成一百万token的耗电量还不到1度电,这成本优势也太恐怖了
♥ 85 ↩ 22
这是 M2 本地跑 LLM 的性能对比,Apple Silicon 在跑 MLX 模型的时候,生成速度也会比 GUFF 快一点,占用的内存也要更小,还发现了一个有趣的事,就是 Apple MLX 引擎在推理的时候,CPU 资源使用量要比跑 GGUF 模型的更高。苹果从 A13 Bionic 开始在 CPU 顶部加入了 AMX 矩阵运算,AMX 运算单元可以加速机器学习的速度,Apple Silicon M 芯片自然也有 AMX 矩阵运算单元,甚至苹果还在 A17 Pro / M3 系列芯片开始为分别为 CPU 大小核的 AMX 单元增加了 AMX 缓存(可以通过 die shot 图看到 AMX 缓存存储单元)。
♥ 85 ↩ 7
从功率到价格,其实M3U的性价比不能说高,对比8卡H20服务器: 并发情况(20Token/s级别的并发):8卡H20并发为35-40,M3U并发是1-2(相当于1:24) 价格情况:8卡H20 8卡141GB版,价格为120万左右,24台M3U价格是7w5×24=180万 功率情况:8卡H20是5000W左右,24台是295W×24=7080W 所以……对于超过16的并发的场景,性价比其实是比H20更低的(顺便H20还有97万的8卡96GB版本)
♥ 78 ↩ 41
油管老外用外置的插座,测出来跑r1-4比特量化时功率是169w,博主叫Dave2D
♥ 68 ↩ 10
个人部署的话阿里的QWQ 32B会更合适,q4需要21GB显存,q8 44GB显存,q16没见到有人部署,估计96G显存够用了。3090,4090可以玩玩q4版。
♥ 65 ↩ 16
不要误导观众,这不是完整版本,这个连8精度都吃不下
♥ 50 ↩ 2
过不久苹果就会拿m4 ultra背刺m3用户了[doge]
♥ 47 ↩ 15
这里放一下八卡系统在vllm环境下的R1 awq推理速度,仅供参考: 8卡 A100 - 38tps 8卡 H100 - 48tps 希望苹果之后还是努力把显卡的GEMM 和SGEMM能力提上去吧。 来源 https://huggingface.co/cognitivecomputations/DeepSeek-R1-AWQ
♥ 45 ↩ 5